




Tabla de contenidos
El Stack ELK: ¿Para qué lo necesito?
Cuando uno se dedica a esto del desarrollo web es muy común acabar administrando varios servidores en los que alojamos docenas de webs. Todas estas webs generan logs continuamente, notificándonos de cada acceso y error que ocurre en cada momento. Pese a que en muchos casos capturar esta información es perfectamente posible con herramientas en el front-end como Google Analytics, los logs internos nos pueden informar de detalles más precisos, en especial en cuanto a errores e información sobre la ejecución de los scripts que mueven nuestros sistemas.
En definitiva, nuestros logs generan toda esta información de gratis, y es nuestro deber como buenos amigos del exceso de información evitar que queden ignorados en algún rincón de nuestros servidores. Hoy vamos a aprender cómo podemos sacarle partido. Con este artículo aprenderás a montar tu propio stack ELK sobre el que experimentar y construir tu propio sistema de monitoreo, con especial énfasis en cómo hacerlo si usas un servidor de hosting Plesk.
Pero antes: ¿Qué es exactamente el stack ELK o Elastic?
Elasticsearch
Elasticsearch es un servidor de búsqueda distribuido, basado en documentos JSON y con una interfaz REST. En otras palabras: Elasticsearch es una base de datos para documentos sin estructura específica especialmente optimizada para procesar búsquedas complejas entre los datos que almacena. En nuestro caso Elasticsearch juega el papel de almacenar las ingentes cantidades de entradas de log que nuestros servidores generarán de forma que podamos analizar la información a gran escala posteriormente.
Por su característica distribuida Elasticsearch puede escalar fácilmente añadiendo nuevas instancias en cluster, acomodándose a nuestro volumen de datos.
Logstash
Nuestro servidores generan logs constantemente, pero dependiendo de qué tecnología usemos, de las versiones de nuestros servidores web y de un sinnúmero de condiciones, el formato de estos logs puede variar. Logstash es la pieza clave que nos permite harmonizar todas estas formas distintas de presentar la información para poder entenderla como un todo en el análisis posterior.
Logstash se basa en tres componentes:
- Inputs, que nos permiten ingerir datos de toda clase de fuentes, como los syslogs de un sistema, bases de datos, logs de Apache e incluso webhooks de Github
- Filters, que interpretan los logs introducidos, transforman la información, generan datos derivados y en general masajean la información a nuestro gusto.
- y Outputs, que nos permiten los datos estructurados resultantes a diferentes servicios como por ejemplo, en nuestro caso, Elasticsearch.
Kibana
Todo lo anterior no tendría mucho sentido si el resultado fuese simplemente otra retahíla de logs que, aun que ahora estructurados y mejorados, no nos aportan mucho más que la información original. Es fundamental por tanto tener una interfaz desde la que visualizar, explorar y analizar esta información.
Esta es la tarea de Kibana, un visualizador de datos para Elasticsearch que nos permite realizar búsquedas, construir gráficos y visualizaciones y disponer de dashboards desde las que tener toda la información bajo control.
Caso de Estudio: Servidor Plesk 17
Escogemos como escenario el siguiente: disponemos de un servidor, dedicado o VPS, con Plesk 17 instalado gestionando un número de sitios web. Además, tendremos un segundo servidor o máquina virtual donde correremos el stack ELK. Éste escenario es bastante común y no os será difícil adaptar la guía a otros similares.
Asumiremos que ambos servidores funcionan sobre Linux, en particular CentOS 7, basado en Red Hat y una de las distribuciones más habituales en entornos de este tipo.
Instalando Elasticsearch, Kibana y Logstash
En nuestro servidor escogido para instalar el Elastic Stack lo primero será, por supuesto, instalar Elasticsearch, Kibana y Logstash. Existen soluciones completas para instalar este conjunto sobre docker (el repositorio deviantony/docker-elk en github es un buen ejemplo) pero optaremos por instalar en local ya que es lo más flexible y cómodo para realizar pruebas.
Como trabajamos con CentOS empezaremos importando las claves publicas de Elastic e instalando su repositorio:
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
sudo vi /etc/yum.repos.d/elastic.repoEn el archivo que acabamos de editar pegaremos el siguiente contenido:
[elastic-5.x]
name=Elastic repository for 5.x packages
baseurl=https://artifacts.elastic.co/packages/5.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-mdInstalando Elasticsearch
Instalar elasticsearch será tan fácil como ejecutar
sudo yum install -y elasticsearchA continuación editaremos el archivo de configuración de Elasticsearch en /etc/elasticsearch/elasticsearch.yml. Deberemos descomentar y editar la línea con la opción network.host, que cambiaremos a localhost. De este modo ningún intruso indeseado podrá conectarse directamente a Elasticsearch desde fuera de nuestro servidor. El resultado será:
network.host: localhostGuardaremos el archivo y a continuación configuraremos el servicio para que se ejecute automáticamente tras reiniciar. Finalmente iniciamos Elasticsearch.
sudo systemctl enable elasticsearch
sudo systemctl start elasticsearchInstalando Kibana
Kibana y Logstash usan el mismo repositorio y claves que Elasticsearch por lo que no será necesario hacer ningún cambio para instalarlo. Sencillamente ejecutamos:
sudo yum install -y kibana
sudo systemctl enable kibana
sudo systemctl start kibanaInstalando Logstash
Instalaremos Logstash del mismo modo que los dos anteriores componentes, y además aprovecharemos la ocasión para instalar un plugin de Logstash que nos facilitará el trabajo más adelante.
sudo yum install -y logstash
sudo /usr/share/logstash/bin/logstash-plugin install logstash-patterns-coreA diferencia de los otros servicios con Logstash no iniciaremos el servicio todavía: es el momento de hablar de configuración.
Configuración de Logstash para Plesk
En logstash es donde tendremos que centrarnos para adaptar el sistema a nuestros logs en particular. En nuestro escenario, como comentábamos al principio, partimos de un servidor Plesk 17.
Análsis de la situación
Por defecto Plesk guarda los logs en /var/www/vhosts/{hostname}/logs/{virtualhost}, donde {hostname} será el hostname de nuestro servidor Plesk y {virtualhost} será la url de cada uno de nuestros sitios alojados.
Esto hace nuestro trabajo algo complicado, ya que tendremos los logs distribuidos entre distintas carpetas.
Desgraciadamente la complejidad no acaba aquí: plesk reparte los logs entre varios archivos para cada sitio. Los que nos interesarán son:
- access_log: Los logs de acceso para peticiones HTTP
- access_ssl_log: Los accesos en peticiones HTTPS
- proxy_access_log y proxy_access_ssl_log: Los logs de acceso para peticiones que son redirigidas al servidor nginx que plesk utiliza para servir los archivos estáticos más eficientemente. Como con los dos anteriores, sin y con SSL, respectivamente.
- error_log: Los errores capturados por Apache
- proxy_error_log: Como en el caso de proxy_access_log, los errores capturados por apache provenientes de la ejecución de peticiones en nginx.
Como podemos ver los logs quedan esparcidos por un buen número de archivos que, además, no tienen un formato común sino que cambian en cada caso. ¡Al ataque!
Enviando la información de Plesk a Logstash: Filebeats
Lo primero que tenemos que solucionar es cómo vamos a hacer llegar todos estos logs distintos a Logstash para ser procesados. En general, y en nuestro escenario en particular, el servidor que corre Plesk y genera los logs es diferente del que mantiene nuestro stack ELK y analizará los datos.
Una solución ideal para ésto es una herramienta llamada Filebeat, desarrollada por los mismos Elastic. La instalaremos en el servidor Plesk. Para ello tendremos que importar las claves y definir el repositorio de Elastic tal y como hemos hecho al instalar Elasticsearch. A continuación haremos:
sudo yum install -y filebeatPara configurarlo editaremos /etc/filebeat/filebeat.yml. La siguiente configuración se adapta a nuestro escenario:
# Filebeat usa "prospectors", que se encargan de extraer el contenido de la fuente.
filebeat.prospectors:
- input_type: log
paths:
- "/var/www/vhosts/el.host.de.nuestro.plesk/logs/*/access_ssl_log"
- "/var/www/vhosts/el.host.de.nuestro.plesk./logs/*/access_log"
- "/var/www/vhosts/el.host.de.nuestro.plesk/logs/*/proxy_access_ssl_log"
- "/var/www/vhosts/el.host.de.nuestro.plesk/logs/*/proxy_access_log"
fields:
# En cada prospector podemos añadir información adicional que se adjuntará a
# cada entrada enviada a Logstash. En este caso indicamos el tipo de log.
log_type: access
- input_type: log
paths:
- "/var/www/vhosts/el.host.de.nuestro.plesk/logs/*/error_log"
- "/var/www/vhosts/el.host.de.nuestro.plesk/logs/*/proxy_error_log"
fields:
log_type: error
output.logstash:
enabled: true
# Finalmente decidimos dónde se envia la información. En nuestro caso nos
# decidimos por enviarla a Logstash para ser procesada antes de llegar a
# Elasticsearch
hosts: ["LA_IP_DE_NUESTRO_SERVIDOR_ELK:5000"]Por supuesto sustituiremos las referencias a el.host.de.nuestro.plesk y LA_IP_DE_NUESTRO_SERVIDOR_ELK por los valores correspondientes.
El siguiente paso es configurar Logstash. Volvemos a nuestro servidor ELK.
Logstash Pipelines
Logstash se fundamenta en el concepto de pipelines. Una pipeline representa una cadena desde un input, que acepta los datos, una serie de filters que los trabajan y un output que envía los datos finales. La siguiente configuración se adaptará a nuestro escenario de ejemplo. Los comentarios os permitirán entender qué hace cada línea.
# Nuestro Input será Filebeats, como hemos determinado anteriormente,
# con el puerto 5000 que hemos configurado en Filebeats
input {
beats {
port => "5000"
}
}filter {
# Este es un filtro Grok. Nos permite analizar un campo de la información
# ingerida (por ejemplo el campo "message", el texto del log por defecto) y
# extraer patrones que se convertirán en nuevos campos en el JSON resultante.
# En este casto analizamos el campo "source" que genera Filebeats con la ruta
# al log del que proviene esta entrada y extraemos el vhost de plesk.
grok {
match => [
"source",
"/var/www/vhosts/el.host.de.nuestro.plesk.example.com/logs/(?[^\/]+)/.*"
]
break_on_match => false
}# En nuestra configuración de filebeats hemos añadido un campo "log_type" para
# diferenciar logs de acceso y de error. Usamos esta información para decidir
# cómo procesar estos datos
if [fields][log_type] == "access" {
# Grok incluye patrones por defecto como %{COMBINEDAPACHELOG} que
# simplifican la tarea de, en este caso, parsear logs de apache.
grok {
match => [ "message", "%{COMBINEDAPACHELOG}" ]
break_on_match => false
}
# El plugin date nos permite interpretar la fecha extraída de los logs
# para que Elasticsearch la use como índice temporal
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
mutate {
remove_field => ["timestamp"]
}
}
if [fields][log_type] == "error" {
# Como en Plesk tenemos errores separados para Apache y Nginx, con
# formatos diferentes, extraemos esta información del nombre del archivo
grok {
match => ["source", "\/(?[a-z\_]+)$"]
break_on_match => false
tag_on_failure => ["__failed_matching_log_type"]
}
# Con la información del tipo de error en nuestras manos, decidimos cómo
# interpretar las entradas
if [error_type] == "proxy_error_log" {
# Los errores encontrados en Nginx tienen un formato complejo que
# nos vemos obligados a parsear manualmente
grok {
match => ["message", "(?\d\d\d\d)\/(?\d\d)\/%{MONTHDAY:monthday} %{HOUR:hour}\:%{MINUTE:minute}\:%{SECOND:second} \[%{LOGLEVEL:error_loglevel}\] (?[0-9\#]+): %{GREEDYDATA:error_message}"]
break_on_match => false
}
mutate {
add_field => {"timestamp" => "%{year}-%{month}-%{monthday}T%{hour}:%{minute}:%{second}"}
}
date {
match => ["timestamp", ISO8601]
}
mutate {
remove_field => ["timestamp"]
}
}
if [error_type] == "error_log" {
# Para los errores de Apache podemos usar un patrón de Grok. Éste en
# particular proviene del plugin 'logstash-patterns-core'
grok {
match => ["message", "%{HTTPD24_ERRORLOG}"]
break_on_match => false
}
date {
match => ["timestamp", "EEE MMM dd HH:mm:ss.SSSSSS yyyy"]
}
mutate {
remove_field => ["timestamp"]
}
}
}
}output {
# Finalmente determinamos la salida de los datos: nuestra instancia Elasticsearch
elasticsearch {
hosts => ["localhost:9200"]
}
}Guardaremos la configuración como /etc/logstash/conf.d/10-plesk.yml e iniciaremos el Logstash
sudo systemctl enable logstash
sudo systemctl start logstashDel mismo modo, en nuestro servidor Plesk, echamos a rodar Filebeat
sudo systemctl enable filebeat
sudo systemctl start filebeatVisualizando con Kibana
Si todo ha ido bien ahora por fin podremos acceder a nuestra instancia de Kibana, que por defecto estará disponible en el puerto 5601 de nuestro servidor ELK. Nos recibirá una pantalla pidiéndonos generar un nuevo índice con los datos recopilados.
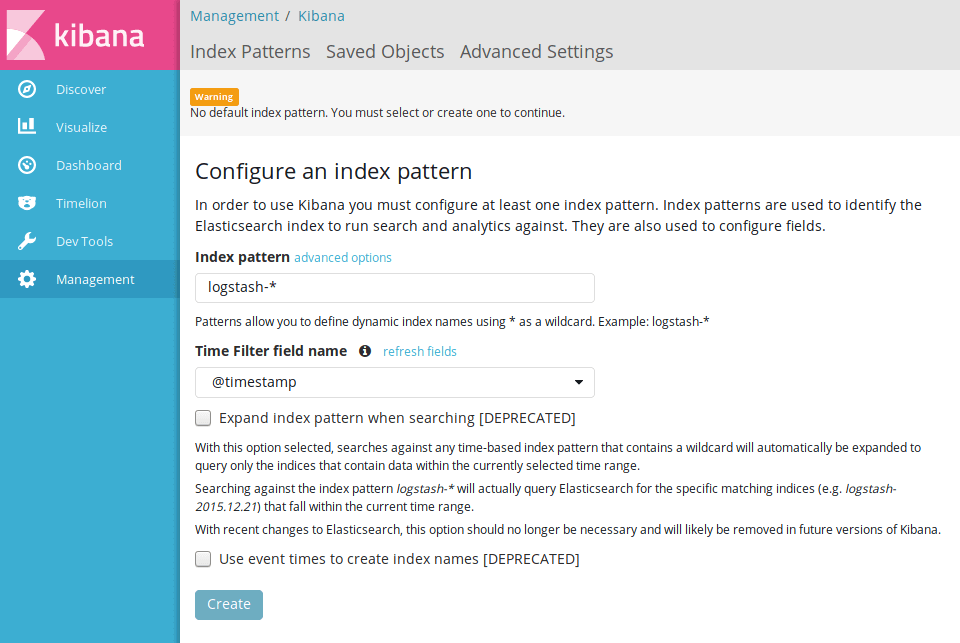
A partir de aquí el mundo del análisis de logs se abre ante nosotros, lo que queda ya fuera del alcance de este artículo. Kibana es una herramienta increíblemente potente y permite crear todo tipo de visualizaciones para tus datos. Recomiendo encarecidamente que le dediquéis unas horas a explorar la extensa documentación en su sitio oficial.
Notas finales: Deploy y Seguridad
El setup que hemos descrito en este post es la forma más sencilla de montar un sistema ELK en cualquier servidor, y es especialmente indicado para desarrollar tus propias visualizaciones, familiarizarte con el entorno y explorar la documentación pues tenemos control total sobre cada servicio que se ejecuta en nuestro sistema.
Para entornos de producción sin embargo será necesario atender a otras necesidades, como la posibilidad de escalar nuestra instancia de Elasticsearch o, muy fundamentalmente, implementar mecanismos de seguridad para que el servidor ELK no esté expuesto a ataques.
Para este último punto estad atentos a las próximas semanas ya que publicaremos una guía de como añadir autenticación por certificado entre el servidor Plesk corriendo Filebeat y el servidor ELK. Además incorporaremos un reverse proxy que nos permitirá proteger con contraseña el panel de Kibana.

